If highlighting doesn’t help students learn, what does? According to Dunlosky et al.’s “Improving Students’ Learning With Effective Learning Techniques” (Psychological Science, 2013), one of the most effective pedagogical techniques is distributed practice. Description:
To-be-learned material is often encountered on more than one occasion, such as when students review their notes and then later use flashcards to restudy the materials, or when a topic is covered in class and then later studied in a textbook. Even so, students mass much of their study prior to tests and believe that this popular cramming strategy is effective. Although cramming is better than not studying at all in the short term, given the same amount of time for study, would students be better off spreading out their study of content? The answer to this question is a resounding “yes.” The term distributed practice
effect refers to the finding that distributing learning over time (either within a single study session or across sessions) typically benefits long-term retention more than does massing learning opportunities back-to-back or in relatively close succession.
Some typical results:
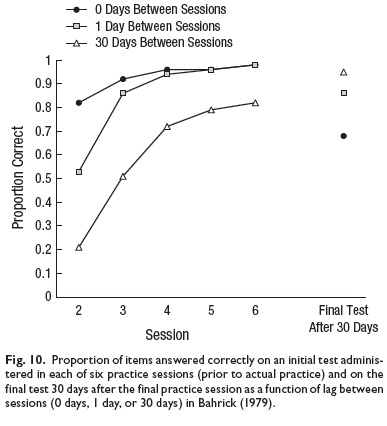
To illustrate the issues involved, we begin with a description of a classic experiment on distributed practice, in which students learned translations of Spanish words to criterion in an original session (Bahrick, 1979). Students then participated in six additional sessions in which they had the chance to retrieve and relearn the translations (feedback was provided). Figure 10 presents results from this study. In the zero-spacing condition (represented by the circles in Fig. 10), the learning sessions were back-to-back, and learning was rapid across the six massed sessions. In the 1-day condition (represented by the squares in Fig. 10), learning sessions were spaced 1 day apart, resulting in slightly more forgetting across sessions (i.e., lower performance on the initial test in each session) than in the zero-spacing condition, but students in the 1-day condition still obtained almost perfect accuracy by the sixth session. In contrast, when learning sessions were separated by 30 days, forgetting was much greater across sessions, and initial test performance did not reach the level observed in the other two conditions, even after six sessions (see triangles in Fig. 10). The key point for our present purposes is that the pattern reversed on the final test 30 days later, such that the best retention of the translations was observed in the condition in which relearning sessions had been separated by 30 days. That is, the condition with the most intersession forgetting yielded the greatest long-term retention. Spaced practice (1 day or 30 days) was superior to massed practice (0 days), and the benefit was greater following a longer lag (30 days)
than a shorter lag (1 day).
Graphically:
Overall:
On the basis of the available evidence, we rate distributed practice as having high utility: It works across students of different ages, with a wide variety of materials, on the majority of standard laboratory measures, and over long delays. It is easy to implement (although it may require some training) and has been used successfully in a number of classroom studies. Although less research has examined distributed-practice effects using complex materials, the existing classroom studies have suggested that distributed practice should work for complex materials as well.
P.S. For a summary of all of Dunlosky et al.’s findings,
.
HT: Nathaniel Bechhofer
READER COMMENTS
Jacky Wong
Sep 21 2015 at 12:29am
Bryan, but as you would agree.. most students study not to learn something for long-term, but to ace the exams. and in this sense, cramming still seems the best method.
jstults
Sep 21 2015 at 1:09am
Interesting stuff, reminds me of spaced reputition (I’ve used it for studying vocabulary flashcards): https://en.m.wikipedia.org/wiki/Spaced_repetition
[broken personal url fixed. Please check your personal url when you paste it in as a url to link around your name or a url you want to recommend to others.–Econlib Ed.]
Yaakov
Sep 21 2015 at 4:19am
These studies are very interesting but are still at a very early stage and should not be used to jump to conclusions on managing classrooms.
Many school books have been designed based on distributed practice, which I know as spiral learning, and I do not see that they are more effective than others. The most important factor in successful learning is actually learning, that is spending time on learning. Getting students to actually learn in school and spend time reading and rehearsing at home will totally mask out the effect of any study tactic.
That is, studying Spanish words for 20 hours (because you will get candy if you succeed on the test, because your teacher put the words in a song you like, because your father will beat the hell out of you if you do not study, because you want to make it to the role of honor, because you are a nerd, because you feel good when you succeed, etc.) will outperform any 10 hour studying regardless of the tactic you use.
Roger Sweeny
Sep 21 2015 at 12:07pm
1) By the time most students get to high school, they have little intrinsic interest in the things they are supposed to learn in school. (Pre-pubescent kids are often docile knowledge-sponges but then something happens …)
2) However, they don’t want to fail their classes. Some even want very high grades.
3) They have found out by experience that the utility maximizing trade-off of study time and grades is to cram the night before the exam.
4) The knowledge gained that way is pretty superficial and “decays” quickly.
5) The knowledge would not decay nearly so much if it continued to be used but most courses are fairly modular. The class does “the Colonial period,” has a test, and then goes on to “the new nation” and never looks back. Math can be an exception.
6) Having study sessions separated by long periods of time forces students to leave their “cram and forget” comfort zone.
blink
Sep 21 2015 at 6:59pm
@ Roger Sweeny generally has it right. As Robin Hanson might summarize, “Studying is not about learning.” Cramming quite effectively meets its real goal: Producing high test grades.
Daniel Ford
Sep 21 2015 at 9:41pm
I’ve been pushing my students towards distributed practice and practice testing by incorporating the Memrise spaced-repetition program into my courses over the past two years. Memrise uses a point system to measure learning and displays it to the public. This allows me to build assignments around having students acquire Memrise points in the courses I prepare for them.
Memrise has its problems and I’m not always happy with the way it’s managed. But I’d recommend it to the Caplan Family School for factual material you never want your kids to forget.
Also a quick correction. Yaakov states in a previous comment that the two methods highly recommended by Dunlosky et. al. are at an early stage. This is false, unless you define “at an early stage” to mean “one-hundred years of research”. This is covered in the article under the practice testing section. For distributed practice the authors don’t mention that the research on it started a century ago, but that should be general knowledge for anyone who has a passing familiarity with the Ebbinghaus forgetting curve.
Fred Anderson
Sep 21 2015 at 9:52pm
I’ve been advising my students of this for at least a decade, maybe two. It isn’t new.
But particularly to Roger Sweeny’s point 3; I suspect they cram because of a Pareto effect — namely, that for 20% of the effort (studying) they’ve learned they can get 80% of the results (grades). Cramming probably won’t get you an A, but it will get you a C. They’re satisficing.
Mark V Anderson
Sep 21 2015 at 10:05pm
Well I can give one anecdote against distributive practice, at least if spiral learning is included. The Elementary schools in Minneapolis adopted spiral learning for Math in a big way, and it was a disaster for my kids. At least in the way it was used in our classrooms, they decided that it didn’t matter so much if the kids learned a particular section very well, because they would come back to it (at a slightly higher level) in a few months. Maybe it worked for the kids good at Math, but for my kids that were not so good it meant that they learned very little. It made me long for the “drill and kill” era. I don’t know if our schools still use this (my kids were in Elementary school 10-20 years ago), but I hope not.
gwern
Sep 22 2015 at 1:26pm
I feel I should point out that experience is not a useful teacher here because students have systematic illusions: when you measure them objectively with tests, the ones who crammed are overconfident about how well they perform. This probably relates to how cramming very briefly produces better recall but then the long-term memory formation doesn’t happen any more than with distributed practice.
eg “Because massing naturally leads to feelings of fluency and increases short-term task performance during learning, learners frequently rate spacing as less effective than massing, even when their performance shows the opposite pattern (Baddeley & Longman 1978; Kornell & Bjork, 2008; Simon & Bjork, 2001; Zechmeister & Shaughnessy, 1980). Averaged across Kornell and Bjork’s (2008) experiments, for example, more than 80% of participants rated massing as equally or more effective than spacing,whereas only 15% of participants actually performed better in the massed condition than in the spaced condition.”
A common theme in the spaced repetition literature – it performs better than massing so consistently and so substantially, and the research literature showing that now spans 3 centuries, that it all naturally makes one wonder why no one uses spacing. The illusions about massing creating better learning because it feels like it does is probably part of it.
Of course, part of the answer here also definitely is signaling: for a lot of classes, you don’t actually want to learn the material, and so spacing is a bad idea. So there’s at least a double-whammy: the people interested in learning feel that massing works so they do massing, and the people who just want the grades find spacing too much of an overhead (and they might learn something).
Roger Sweeny
Sep 23 2015 at 9:04am
gwern,
I completely agree that cramming does not maximize learning, and any student who thinks it does is deluding him- or herself. However, learning is not most students’ goal in most classes. The most common goals are to get credit and to build a transcript.
I think many of the people who actually do want to learn are thinking about the material, asking themselves questions, puzzling over things, maybe even talking about the material with other students who are interested in learning–and thus inadvertently “spacing.”
Comments are closed.